2. Background theory¶
2.1. Introduction¶
The EM1DTM and EM1DTMFWD programs are designed to interpret time-domain, small loop, electromagnetic data over a 1D layered Earth. These programs model the Earth’s time-domain electromagnetic response due to a small inductive loop source which carries a sinusoidal time-varying current. The data are the secondary magnetic field which results from currents and magnetization induced in the Earth.
2.1.1. Details regarding the source and receiver¶
EM1DTM and EM1DTMFWD assume that the transmitter loop is horizontal. The programs also assume that each receiver loop is sufficiently small and that they may be considered point receivers; i.e. the spatial variation in magnetic flux through the receiver loop is negligible.
2.1.2. Details regarding the domain¶
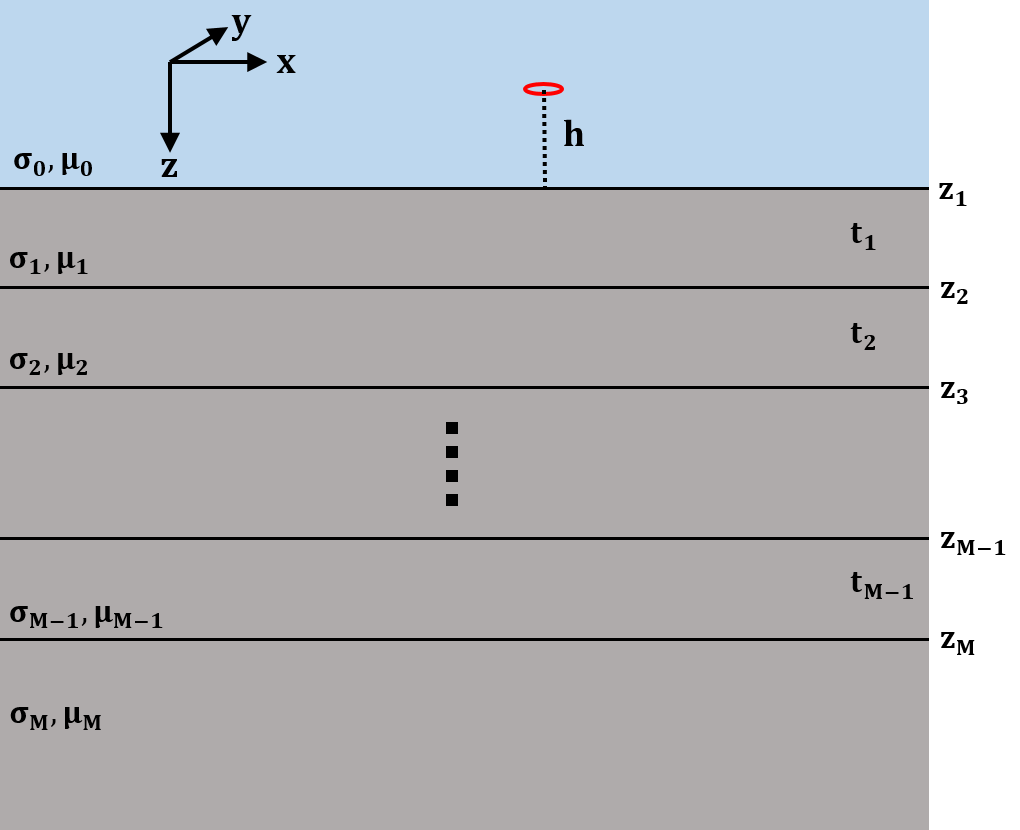
Fig. 2.1 Layered 1D model describing the Earth for each sounding.
EM1DTM and EM1DTMFWD model the Earth’s response for measurements above a stack of uniform, horizontal layers. The coordinate system used for describing the Earth models has z as positive downwards, with the surface of the Earth at z=0. The z-coordinates of the source and receiver locations (which must be above the surface) are therefore negative. Each layer is defined by a thickness and an electrical conductivity. It is the physical properties of the layers that are obtained during the inversion of all measurements gathered at a single location, with the depths to the layer interfaces remaining fixed. If measurements made at multiple locations are being interpreted, the corresponding one-dimensional models are juxtaposed to create a two- dimensional image of the subsurface.
All measurements that are to be inverted for a single one- dimensional model must be grouped together as a “sounding”. A sounding can be considered a distinct collection of TEM measurements (receivers and times) for a given transmitter. Each different sounding is inverted for a separate one- dimensional model.
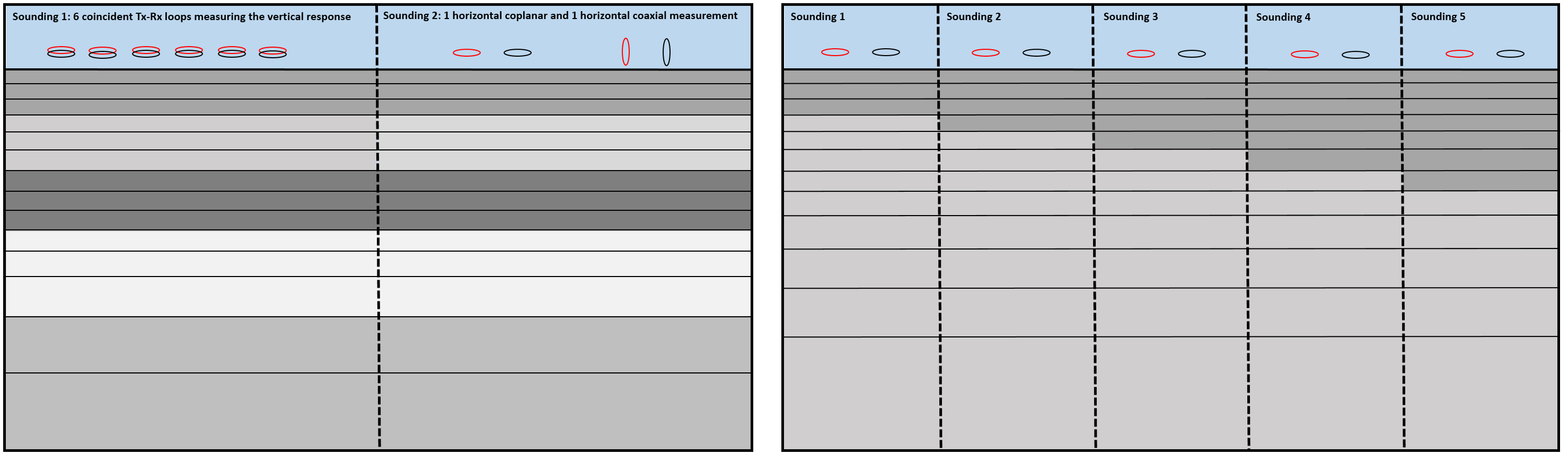
Fig. 2.2 Two distinct groupings of transmitters and receivers (soundings) at the same location (left). Different soundings used to map lateral variation in the Earth (right). Click to enlarge.
The electrical conductivity of Earth materials varies over several orders of magnitude, making it more natural to invert for the logarithms of the layer conductivities rather than the conductivities themselves. This also ensures that conductivities in the constructed model are positive.
2.1.3. Details regarding the data¶
For a horizontal loop source, EM1DTM and EM1DTMFWD can handle any combination of:
- times for the transmitter current
- separations and heights for the transmitter and receiver(s)
- B-field or time varying (dBdt) response
- x, y and z-components of the response
Programs EM1DTM and EM1DTMFWD accept observations in two different forms: values of the secondary magnetic field H-field in A/m and values of the total H-field in A/m. If the transmitter and receiver have the same orientation, the x-, y- and z-components of the secondary field are normalized by the x-, y- and z-components of the free-space field respectively. If the transmitter and receiver have different orientations, the secondary field is normalized by the magnitude of the free-space field.
2.2. Forward Modeling¶
The method used to compute the magnetic field values for a particular source- receiver arrangement over a layered Earth model is the matrix propagation approach described in Farquharson ([Farquharson2003]). The method uses the z-component of the Schelkunoff F-potential ([Ward1987]): layered Earth model is the matrix propagation approach described in Farquharson & Oldenburg (1996) and Farquharson, Oldenburg & Routh (2003). Computations are done in the frequency domain, then the fields transformed to the time domain.
This section covers the aspects of the forward-modelling procedure for the three components of the magnetic field above a horizontally-layered Earth model for a horizontal, many-sided transmitter loop also above the surface of the model. The field for the transmitter loop is computed by the superposition of the fields due to horizontal electric dipoles (see eqs.~4.134–4.152 [Ward1987]). Because the loop is closed, the contributions from the ends of the electric dipole are ignored, and the superposition is carried out only over the TE-mode component. This TE-mode only involves the z-component of the Schelkunoff \(\mathbf{F}\)-potential, just as for program EM1DFM.
The Schelkunoff F-potential is defined as follows:
where \(\mathbf{E}\) and \(\mathbf{H}\) are the electric and mangetic fields, \(\sigma\) and \(\mu\) are the conductivity and permability of the uniform region to which the above queation refer, and a time-dependence of \(e^{i\omega t}\) has been assumed.
In the \(j^{th}\) layer (\(j > 0\)), with conductivity \(σj\) , and permeability \(µ_j\), the z-component of the Schelkunoff potential satisfies the equation (assuming the quasi-static approximation, and the permeability of the layer is equal to that of free space \(\mu_0\)):
The propagation of F through the stack of layers therefore happens in exactly the same way, and so is not repeated here (see EM1DFM Forward modeling section).
Note
- Assumptions
- \(e^{i\omega t}\) time-dependence (just as in [Ward1987])
- quasi-static approximation throughout
- z positive downwards
- air halfspace (\(\sigma=0\)) for z<0, piecewise constant model (\(\sigma>0\)) of N layers for zge0, \(N^{th}\) layer being the basement (i.e.~homogeneous) halfspace
- magnetic permeability everywhere equal to that of free space.
From the propagation of F through the layers gives the following expression for the kernel of the Hankel transform, \(\tilde{F}\), in the air halfspace (\(z<0\)):
(same as here in EM1DFM).
For a horizontal \(x\)-directed electric dipole at a height \(h\) (i.e., \(z=-h\), \(h>0\)) above the surface of the layered Earth, the downward-decaying part of the primary solution of \(\tilde{F}\) (and the only downward-decaying part of the solution in the air halfspace) at the surface of the Earth (\(z=0\)) is given by
from [Ward1987], equation (4.137). Substituting (2.2) into (2.1) gives
Generalizing this expression for \(z\) above (\(z<-h\)) as well as below the source (\(z>-h\)):
Applying the inverse Fourier transform to (2.4) gives
(equation (4.139) of [Ward1987]). Using the identity
([Ward1987], equation (2.10)) where \(\lambda^2=k_x^2+k_y^2\) and \(r^2=x^2+y^2\), (2.5) can be rewritten as
since
([Ward1987], equation 4.44 (almost)).
The \(H\)-field in the air halfspace can be obtained from (2.9) (or (2.8)) by using equation (1.130) of [Ward1987]:
since \(\kappa_0^2=0\). Applying (2.11) to (2.9) gives
(The plus/minus is to do with whether or not the observation location is above or below the source. In the program, it perhaps it is only the secondary fields that are computed using the above expressions: the primary field, which corresponds to the first term in each Hankel transform kernel above is computed using its for in \((x,y,z)\)-space.) When the above expression for a horizontal electric dipole is integrated along a wire all that is left is the effects of the endpoints. These will cancel when integrating around the closed loop. So as far as the part of \(H_x\) that contributes to the file due to a closed loop:
For the \(y\)-component of the H-field, first consider differentiating the expression for \(F_0\) in (2.5) with respect to \(y\):
since
Converting the \(k_x^2\) into derivatives with respect to \(x\), and converting the two-dimensional Fourier transforms to Hankel transforms gives
using equations (4.144) and (4.117) of [Ward1987]. Differentiating (2.22) with respect to \(z\) and scaling by \(i\omega\mu_0\) (see (2.12)) gives
(equation 4.150 of [Ward1987]). The second integral in the above expression only contributes at the ends of the dipole. So the only part of \(H_y\) required to compute the field due to the closed loop is
Finally, applying (2.14) to (2.9) gives the \(z\)-component of the H-field:
(equation (4.152) of [Ward1987]).
(2.24) and (2.25) are for the total H-field (\(H_x=0\) from (2.16) for an \(x\)-directed electric dipole excluding the effects at the end-points, that is, the wholespace field up in the air plus the field due to currents induced in the layered Earth. In (2.24) and (2.25), the first part of the kernel of the Hankel transform corresponds to the primary wholespace field:
and
From [Ward1987] equation (4.53), the integral in the above two expressions can be done:
So
(equation (2.42) of [Ward1987] for \(\sigma=0\)), and
(equation (2.42) of [Ward1987] for \(\sigma=0\)).
2.2.1. Frequency- to time-domain transformation – Part I¶
The solution for the H-field in the frequency domain for a delta-function source in time (and hence a flat, constant, real source term in the frequency domain) is, for example,
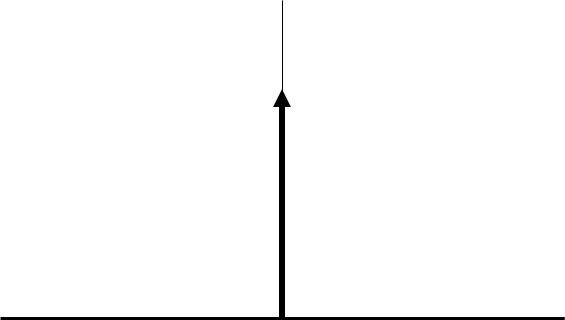
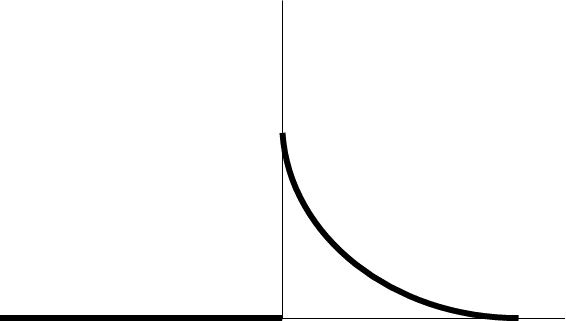
Doing the inverse Fourier transform of these kinds of expressions does not encounter any subtleties, and gives an H-field as a function of time that, schematically, looks like:
| \(S(t)=\delta(t)\quad\) | \(\rightarrow\) | \(G^h(t)\quad\) |
|---|---|---|
|
|
This is the basic response that program EM1DTM computes. Notation of \(G^h(t)\) because this is the Green’s function for convolution with the transmitter current waveform \(S(t)\) to give the H-field:
The H-field for the delta-function source, that is, \(G^h\) certainly exists for \(t>0\). Also, it is certainly zero for \(t<0\). And at \(t=0\), it certainly is not infinite (not physical). Let’s re-describe the function \(G^h\) (shown in the diagram above) as
where \(\tilde{G}^h(t)\) is equal to \(G^h\) for \(t>0\), \(\tilde{G}^h(0)=\lim_{t\rightarrow 0+}G^h\), and does anything it wants for \(t<0\). And \(X(t)\) is the Heaviside function. This moves all issues about what is happening at \(t=0\) into the Heaviside function.
For measurements of voltage, the Green’s function (impulse response) that is required is the time derivative of \(G^h\) (and for all \(t\), not just \(t>0\)). Schematically:
| \(S(t)=\delta(t)\quad\) | \(\rightarrow\) | \(G^V(t)\quad\) |
|---|---|---|
|
|
|
In terms of math:
Let’s take the time derivative of (2.37) to get the full expression for \(G^V\):
where \(\delta\) is the delta function. Now, this is not a time derivative that should be happening numerically. So, given the basic \(G^h(t)\) and some representation of the transmitter current waveform \(S(t)\), program EM1DTM currently uses the re-arrangement of (2.38) given by the substitution of (2.39) into (2.38) followed by some integration by parts:
where the Heaviside function has been used to restrict the limits of the integration. Now doing the integration by parts:
Which looks as though it has the expected additional non-convolution-integral term.
However, perhaps there should be an additional minus sign in going from AA--4 to
the one before (2.40) because the derivative has changed from \(d/dt\) to \(d/dt^{\prime}\).
But perhaps not.
2.2.2. Frequency- to time-domain transformation¶
The Fourier transform that was applied to Maxwell’s equations to get the frequency-domain equations was (see [Ward1987], equation (1.1))
and the corresponding inverse transform is
For the frequency domain computations, it is assumed that the source term is the same for all frequencies. In other words, a flat spectrum, which corresponds to a delta-function time-dependence of the source.
Consider at the moment a causal signal, that is, one for which \(f(t)=0\) for \(t<0\). The Fourier transform of this signal is then
Note that because of the dependence of the real part of \(F(\omega)\) on \(\cos\,\omega t\) and of the imaginary part on \(\sin\,\omega t\), the real part of \(F(\omega)\) is even and the imaginary part of \(F(\omega)\) is odd. Hence, \(f(t)\) can be obtained from either the real or imaginary part of its Fourier transform via the inverse cosine or sine transform:
(For factor of \(\,2/\pi\,\) see, for example, Arfken.)
Now consider that we’ve computed the H-field in the frequency domain for a uniform source spectrum. Then from the above expressions, the time-domain H-field for a \(^{th}\) positive delta-function} source time-dependence is
where \(H(\omega)\) is the frequency-domain H-field for the uniform source spectrum. For a \(^{th}\) negative delta-function} source:
The negative delta-function source dependence is the derivative with respect to time of a step turn-off source dependence. Hence, the \(^{th}\) derivative} of the time-domain H-field due to a \(^{th}\) step turn-off} is also given by the above expressions:
Integrating the above two expressions gives the H-field for a \(^{th}\) step turn-off} source:
(See also Newman, Hohmann and Anderson, and Kaufman and Keller for all this.)
Thinking in terms of the time-domain inhomogeneous differential equation:
| Fake / equivalent world | Real World | |||
|---|---|---|---|---|
|
|
\(\;\&\;\mathbf{h(t)}\) | \(\Leftrightarrow\) | 
|
\(\;\&\;\mathbf{\frac{\partial h}{\partial t}(t)}\) |
|
\(\;\&\;\mathbf{h(t)}\) | \(\Leftrightarrow\) | 
|
\(\;\&\;\mathbf{\frac{\partial h}{\partial t}(t)}\) |
Top left is what we know (flat frequency spectrum for the source and sine transform of the imaginary part of the field), and top right is what we’re after. Also, bottom right is obtained from top left by convolution with the box-car, and bottom right is what we’re considering it to be. Note that there should really be some minus signs in the above diagram.
| Fake / equivalent world | Real World | |||
|---|---|---|---|---|
|
|
\(\;\&\;\mathbf{\int^t h(t\prime) dt\prime}\) | \(\Leftrightarrow\) |
|
\(\;\&\;\mathbf{h(t)}\) |
|
|
\(\;\&\;\mathbf{\int^t h(t\prime) dt\prime}\) | \(\Leftrightarrow\) |
|
\(\;\&\;\mathbf{h(t)}\) |
Again, top left is what we know (flat frequency spectrum for the source and sine transform of the imaginary part of the field), and top right is what we’re after. Also, bottom right is obtained from top left by convolution with the box-car, and bottom right is what we’re considering it to be. Note that there should really be some minus signs in the above diagram.
| Fake / equivalent world | Real World | |||
|---|---|---|---|---|
|
\(\;\&\;\mathbf{h(t)}\) | \(\Leftrightarrow\) |
|
\(\;\&\;\mathbf{\frac{\partial h}{\partial t}(t)}\) |
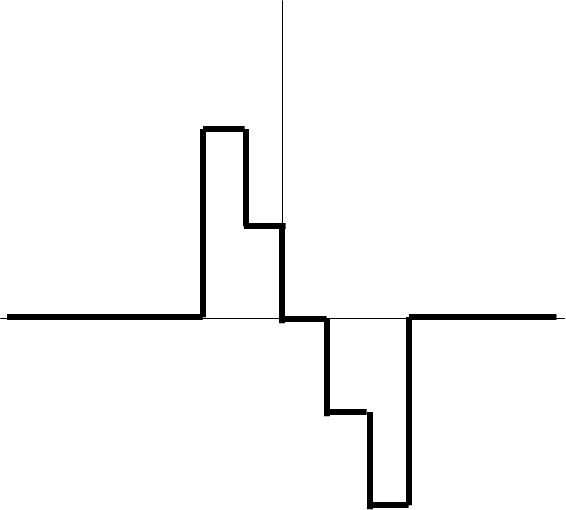
|
\(\;\&\;\mathbf{h(t)}\) | \(\Leftrightarrow\) | 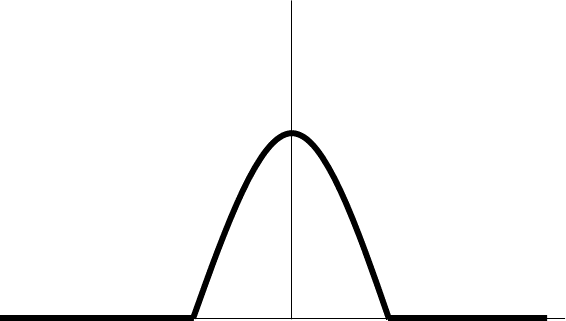
|
\(\;\&\;\mathbf{\frac{\partial h}{\partial t}(t)}\) |
Top left is what we have, and right is what we’re thinking it is. Bottom left is the convolution with a discretized half-sine, and bottom right is what we’re considering it to be: the time-derivative of the H-field for a half-sine waveform.
2.2.3. Integration of cubic splined function¶
The time-domain voltage or magnetic field ends up being known at a number of discrete, logarithmically/ exponentially-spaced times as a result of Anderson’s cosine/sine digital transform. This time-domain function is cubic splined in terms of the logarithms of the times. Hence, between any two discrete times, the time-domain function is approximated by the cubic spline
(see routines RSPLN and RSPLE) where \(h=\log x-\log t_i\), \(x\) is the time at which the function \(y\) is required, \(t_i\) is the \(i^{th}\) time at which \(y\) is known (\(t_i\le x\le t_{i+1}\)), \(y_0=y(\log t_i)\), and \(q_1\), \(q_2\) and \(q_3\) are the spline coefficients. The required integral is
Substituting the polynomial expression for \(y(h)\) into the above integral and worrying about each term individually gives:
(G and R 2.322.1),
(G and R 2.322.2), and
(G and R 2.322.3). Hence, summing the integrals above,
The original plan was to treat a discretised transmitter current waveform as a piecewise linear function (\(^{th}\) i.e.), straight line segments between the provided sampled points), which meant that the response coming out of Anderson’s filtering routine was convolved with the piecewise constant time-derivative of the transmitter current waveform to give voltages. This proved to be not good enough for on-time calculations (the step-y nature of the approximation of the time derivative of the transmitter current waveform could be seen in the computed voltages). So it was decided to cubic spline the transmitter current waveform, which gives a piecewise quadratic approximation to the time derivative of the waveform. And so the convolution of the stuff coming out of Anderson’s routine is now with a constant, a linear time term and a quadratic term. The involved integral above is still required, along with:
Using the integrals above for the various powers of \(h\) times \(e^h\), the relevant integrals for the various parts of the cubic spline representation of \(y(h)\) are:
The limits for the integral are \(h=\log a - \log t_i\) and \(h=\log b - \log t_i\). The term \(e^{2h}\) becomes:
where \(X\) is either \(a\) or \(b\). Hence,
And
And
Hence,
bigskip In the previous two integrals of the product of \(x\) and \(x^2\) with the function splined in terms of \(\log x\), the \(x\) and \(x^2\) should really be \((B-x)\) and \((B-x)^2\), where \(B\) is the end of the relevant interval of the splined transmitter current waveform (because it’s convolution that’s happening):
and
Also, it was not really \(x\) and \(x^2\) in those integrals because these terms are coming from the cubic splining of the transmitter current waveform, which means that in each interval between discretization points, it should be \((x-A)\) and \((x-A)^2\) that are involved, where \(A\) is the start of the relevant interval for the transmitter current waveform. Because
and
then
2.2.4. Computing Sensitivities¶
The inverse problem of determining the conductivity and/or susceptibility of the Earth from electromagnetic measurements is nonlinear. Program EM1DTM uses an iterative procedure to solve this problem. At each iteration the linearized approximation of the full nonlinear problem is solved. This requires the Jacobian matrix for the sensitivities, \(\mathbf{J} = (\mathbf{J^\sigma}, \mathbf{J^\kappa})\) where:
in which \(d_i\) is the \(i^{th}\) observation, and \(\sigma_j\) and \(\kappa_j\) are the conductivity and susceptibility of the \(j^{th}\) layer.
The algorithm for computing the sensitivities is obtained by differentiating the expressions for the H-fields with respect to the model parameters ([Farquharson2003]). For example, the sensitivity with respect to \(m_j\) (either the conductivity or susceptibility of the \(j^{th}\) layer) of the z-component of the H-field for a z-directed magnetic dipole source is given by:
The derivative of the coefficient is simply:
where \(P_{11}\) and \(P_{21}\) are elements of the propagation matrix \(\mathbf{P}\). The derivative of \(\mathbf{P}\) with respect to \(m_j\) (for \(1 \leq j \leq M-1\)) is
The sensitivities with respect to the conductivity and susceptibility of the basement halfspace are given by
The derivatives of the individual layer matrices with respect to the conductivities and susceptibilities are straightforward to derive, and are not given here.
Just as for the forward modelling, the Hankel transform in eq. (2.43), and those in the corresponding expressions for the sensitivities of the other observations, are computed using the digital filtering routine of Anderson ([Anderson1982]).
The partial propagation matrices
are computed during the forward modelling, and saved for re-use during the sensitivity computations. This sensitivity-equation approach therefore has the efficiency of an adjoint-equation approach.
2.3. Inversion Methodologies¶
In program EM1DTM, there are four different inversion algorithms. They all have the same general formulation, but differ in their treatment of the trade-off parameter (see fixed trade-off, discrepency principle, GCV and L-curve criterion).
2.3.1. General formulation¶
The aim of each inversion algorithm is to construct the simplest model that adequately reproduces the observations. This is achieved by posing the inverse problem as an optimization problem in which we recover the model that minimizes the objective function:
The two components of this objective function are as follows. \(\phi_d\) is the data misfit:
where \(d^{obs}\) is the vector containing the \(N\) observations, \(\mathbf{d}\) is the forward-modelled data and \(M_d(\mathbf{x})\) is some measure of the lenght of a vector \(\mathbf{x}\). It is assumed that the noise in the observations is Gaussian and uncorrelated, and that the estimated standard deviation of the noise in the \(i^{th}\) observation is of the form \(s_0 \hat{s}_i\), where \(\hat{s}_i\) indicates the amount of noise in the \(i^{th}\) observation relative to that in the others, and is a scale factor that specifies the total amount of noise in the set of observations. The matrix \(\mathbf{W_d}\) is therefore given by:
The model-structure component of the objective function is \(\phi_m\). In its most general form it contains four terms:
where \(\mathbf{m^\sigma}\) is the vector containing the logarithms of the layer conductivitiesq. The matrix \(\mathbf{W_s^\sigma}\) is:
where \(t_j\) is the thickness of the \(j^{th}\) layer. And the matrix \(\mathbf{W_z^\sigma}\) is:
The rows of any of these two weighting matrices can be scaled if desired (see file for additional model-norm weights). The vectors \(\mathbf{m_s^{\sigma , ref}}\) and \(\mathbf{m_z^{\sigma , ref}}\) contain the layer conductivities for the two possible reference models. The two terms in \(\phi_m\) therefore correspond to the “smallest” and “flattest” terms for the conductivity parts of the model. The relative importance of the two terms is governed by the coefficients \(\mathbf{\alpha_s^{\sigma}}\) and \(\mathbf{\alpha_z^{\sigma}}\), which are discussed in the Fundamentals of Inversion. The trade-off parameter :math:beta` <http://giftoolscookbook .readthedocs.io/en/latest/content/fundamentals/Beta.html#the-beta-parameter- trade-off>`_ balances the opposing effects of minimizing the misfit and minimizing the amount of structure in the model. It is the different ways in which \(\beta\) is determined that distinguish the four inversion algorithms in program EM1DTM from one another. They are described in the next sections.
2.3.2. General Norm Measures¶
Program EM1DTM uses general measures of the “length” of a vector instead of the traditional sum-of- squares measure. (For more on the use of general measures in nonlinear inverse problems see Farquharson & Oldenburg, 1998). Specifically, the measure used for the measure of data misfit, \(M_d\), is Huber’s \(M\) -measure:
where
This measure is a composite measure, behaving like a quadratic (i.e., sum-of- squares) measure for elements of the vector less that the parameter c, and behaving like a linear (i.e., \(l_1\)-norm) measure for elements of the vector larger than \(c\). If \(c\) is chosen to be large relative to the elements of the vector, \(M_d\) will give similar results to those for the sum-of-squares measure. For smaller values of \(c\), for example, when \(c\) is only a factor of 2 or so greater than the average size of an element of the vector, \(M_d\) will act as a robust measure of misfit, and hence be less biased by any outliers or other non-Gaussian noise in the observations.
The measure used for the components of the measure of model structure, \(M_m^s\) and \(M_m^z\) is the \(l_p\)-like measure of Ekblom:
where
The parameter \(p\) can be used to vary the behaviour of this measure. For example, with \(p = 2\), this measure behaves like the sum-of-squares measure, and a model constructed using this will have the smeared-out, fuzzy appearance that is characteristic of the sum-of-squares measure. In contrast, for p = 1, this measure does not bias against large jumps in conductivity from one layer to the next, and will result in a piecewise-constant, blocky model. The parameter \(\epsilon\) is a small number, considerably smaller than the average size of an element of the vector. Its use is to avoid the numerical difficulties for zero-valued elements when \(p < 2\) from which the true \(l_p\)-norm suffers. In program EM1DTM, the values of p can be different for the smallest and flattest components of \(\phi_m\) .
2.3.3. General Algorithm¶
As mentioned in the computing sensitivities section, the inverse problem considered here is nonlinear. It is solved using an iterative procedure. At the \(n^{th}\) iteration, the actual objective function being minimized is:
In the data misfit \(\phi_d^n\), the forward-modelled data \(\mathbf{d}^n\) are the data for the model that is sought at the current iteration. These data are approximated by:
where \(\delta \mathbf{m} = \mathbf{m}^{n} - \mathbf{m}^{n-1}\;\) and \(\mathbf{J}^{n-1}\) is the Jacobian matrix given by (2.42) and evaluated for the model from the previous iteration. At the \(n^{th}\) iteration, the problem to be solved is that of finding the change, (\(\delta \mathbf{m} , \delta \mathbf{m}^\kappa\)) to the model which minimizes the objective function \(\Phi^n\). Differentiating eq. (2.50) with respect to the components of \(\delta \mathbf{m}\) and \(\delta \mathbf{m}^\kappa\), and equating the resulting expressions to zero, gives the system of equations to be solved. This is slightly more involved now that \(\phi_d\) amd \(\phi_m\) comprise the Huber’s \(M\)-measure (2.46) and Ekblom’s \(l_p\)-like measure, rather than the usual sum-of-squares measures. Specifically, the derivative of (2.47) gives:
where \(x =W_d(\mathbf{d}^{n-1} + \mathbf{J}^{n-1} \delta \mathbf{m} - \mathbf{d}^{obs}\). The vector of the derivatives with respect to the perturbations of the model parameters in all the layers can be written in matrix notation as:
The linear system of equations to be solved for :math:`delta mathbf{m} is therefore:
where \(T\) denotes the transpose and:
where \(\mathbf{\hat{X}}^{n-1} = \textrm{diag} \{ m_1^{\kappa, n-1}, ... , m_M^{\kappa, n-1} \}\). The solution to eq. (2.52) is equivalent to the least-squares solution of:
Once the step \(\delta \mathbf{m}\) has been determined by the solution of eq. (2.52) or eq. (2.53), the new model is given by:
There are two conditions on the step length \(\nu\). First, if positivity of the layer susceptibilities is being enforced:
must hold for all \(j=1,...,M\). Secondly, the objective function must be decreased by the addition of the step to the model:
where \(\phi_d^n\) is now the misfit computed using the full forward modelling for the new model \(\mathbf{m}^n\). To determine \(\mathbf{m}^n\), a step length (\(\nu\)) of either 1 or the maximum value for which eq. (2.55) is true (whichever is greater) is tried. If eq. (2.56) is true for the step length, it is accepted. If eq. (2.56) is not true, \(\nu\) is decreased by factors of 2 until it is true.
2.3.4. Algorithm 1: fixed trade-off parameter¶
The trade-off parameter, \(\beta\), remains fixed at its user-supplied value throughout the inversion. The least- squares solution of eq. (2.53) is used. This is computed using the subroutine “LSQR” of Paige & Saunders ([Paige1982]). If the desired value of \(\beta\) is known, this is the fastest of the four inversion algorithms as it does not involve a line search over trial values of \(\beta\) at each iteration. If the appropriate value of \(\beta\) is not known, it can be found using this algorithm by trail-and-error. This may or may not be time-consuming.
2.3.5. Algorithm 2: discrepancy principle¶
If a complete description of the noise in a set of observations is available - that is, both \(s_0\) and \(\hat{s}_i \: (i=1,...,N)\) are known - the expectation of the misfit, \(E (\phi_d)\), is equal to the number of observations \(N\). Algorithm 2 therefore attempts to choose the trade-off parameter so that the misfit for the final model is equal to a target value of \(chifac \times N\). If the noise in the observations is well known, \(chifac\) should equal 1. However, \(chifac\) can be adjusted by the user to give a target misfit appropriate for a particular data-set. If a misfit as small as the target value cannot be achieved, the algorithm searches for the smallest possible misfit.
Experience has shown that choosing the trade-off parameter at early iterations in this way can lead to excessive structure in the model, and that removing this structure once the target (or minimum) misfit has been attained can require a significant number of additional iterations. A restriction is therefore placed on the greatest-allowed decrease in the misfit at any iteration, thus allowing structure to be slowly but steadily introduced into the model. In program EM1DTM, the target misfit at the \(n^{th}\) iteration is given by:
where the user-supplied factor \(mfac\) is such that \(0.1 \leq mfac \leq 0.5\).
The step \(\delta \mathbf{m}\) is found from the solution of eq. (2.53) using subroutine LSQR of Paige & Saunders ([Paige1982]). The line search at each iteration moves along the \(\phi_d\) versus log \(\! \beta\) curve until either the target misfit, \(\phi_d^{n, tar}\), is bracketed, in which case a bisection search is used to converge to the target, or the minimum misfit (\(> \phi_d^{n-1}\)) is bracketed, in which case a golden section search (for example, Press et al., 1986) is used to converge to the minimum. The starting value of \(\beta\) for each line search is \(\beta^{n-1}\). For the first iteration, the \(\beta \, (=\beta_0)\) for the line search is given by \(N/\phi_m (\mathbf{m}^\dagger)\), where \(\mathbf{m}^\dagger\) contains typical values of conductivity and/or susceptibility. Specifically, \(\mathbf{m}^\dagger\) is a model whose top \(M/5\) layers have a conductivity of 0.02 S/m and susceptibility of 0.02 SI units, and whose remaining layers have a conductivity of 0.01 S/m and susceptibility of 0 SI units. Also, the reference models used in the computation of \(\phi_m (\mathbf{m}^\dagger )\) are homogeneous halfspaces of 0.01 S/m and 0 SI units. The line search is efficient, but does involve the full forward modelling to compute the misfit for each trial value of \(\beta\).
2.3.6. Algorithm 3: GCV criterion¶
If only the relative amount of noise in the observations is known - that is, \(\hat{s}_i (i=1,...,N)\) is known but not \(s_0\) - the appropriate target value for the misfit cannot be determined, and hence Algorithm 2 is not the most suitable. The generalized cross-validation (GCV) method provides a means of estimating, during the course of an inversion, a value of the trade-off parameter that results in an appropriate fit to the observations, and in so doing, effectively estimating the level of noise, \(s_0\), in the observations (see, for example, [Wahba1990]; [Hansen1998]).
The GCV method is based on the following argument ([Wahba1990]; [Haber1997]; [Haber2000]). Consider inverting all but the first observation using a trial value of \(\beta\), and then computing the individual misfit between the first observation and the first forward-modelled datum for the model produced by the inversion. This can be repeated leaving out all the other observations in turn, inverting the retained observations using the same value of \(\beta\), and computing the misfit between the observation left out and the corresponding forward-modelled datum. The best value of \(\beta\) can then be defined as the one which gives the smallest sum of all the individual misfits. For a linear problem, this corresponds to minimizing the GCV function. For a nonlinear problem, the GCV method can be applied to the linearized problem being solved at each iteration ([Haber1997]; [Haber2000]; [Li2003]; [Farquharson2000]). From eq. (2.52), the GCV function for the \(n^{th}\) iteration is given by:
where
and \(\mathbf{\hat{d} - d^{obs} - d}^{n-1}\). If \(\beta^*\) is the value of the trade-off parameter that minimizes eq. (2.58) at the \(n^{th}\) iteration, the actual value of \(\beta\) used to compute the new model is given by:
where the user-supplied factor \(bfac\) is such that \(0.01<bfac<0.5\). As for Algorithm 2, this limit on the allowed decrease in the trade-off parameter prevents unnecessary structure being introduced into the model at early iterations. The inverse of the matrix \(\mathbf{M}\) required in eq. (2.58), and the solution to eq. (2.52) given this inverse, is computed using the Cholesky factorization routines from LAPACK ([Anderson1999]). The line search at each iteration moves along the curve of the GCV function versus the logarithm of the trade-off parameter until the minimum is bracketed (or \(bfac \times \beta^{n-1}\) reached), and then a golden section search (e.g., Press et al., 1986) is used to converge to the minimum. The starting value of \(\beta\) in the line search is \(\beta^{n-1}\) ( \(\beta^0\) is estimated in the same way as for Algorithm 2). This is an efficient search, even with the inversion of the matrix \(\mathbf{M}\).
2.3.7. Algorithm 4: L-curve criterion¶
As for the GCV-based method, the L-curve method provides a means of estimating an appropriate value of the trade-off parameter if only \(\hat{s}_i, \, i=1,...,N\) are known and not \(s_0\). For a linear inverse problem, if the data misfit \(\phi_d\) is plotted against the model norm \(\phi_m\) for all reasonable values of the trade-off parameter \(\beta\), the resulting curve tends to have a characteristic “L”-shape, especially when plotted on logarithmic axes (see, for example, [Hansen1998]). The corner of this L-curve corresponds to roughly equal emphasis on the misfit and model norm during the inversion. Moving along the L-curve away from the corner is associated with a progressively smaller decrease in the misfit for large increases in the model norm, or a progressively smaller decrease in the model norm for large increases in the misfit. The value of \(\beta\) at the point of maximum curvature on the L-curve is therefore the most appropriate, according to this criterion.
For a nonlinear problem, the L-curve criterion can be applied to the linearized inverse problem at each iteration (Li & Oldenburg, 1999; Farquharson & Oldenburg, 2000). In this situation, the L-curve is defined using the linearized misfit, which uses the approximation given in eq. (2.51) for the forward-modelled data. The curvature of the L-curve is computed using the formula (Hansen, 1998):
where \(\zeta = \textrm{log} \, \phi_d^{lin}\) and \(\eta = \textrm{log}\, \phi_m\). The prime denotes differentiation with respect to log \(\beta\). As for both Algorithms 2 & 3, a restriction is imposed on how quickly the trade-off parameter can be decreased from one iteration to the next. The actual value of \(\beta\) chosen for use at the \(n^{th}\) th iteration is given by eq. (2.59), where \(\beta^*\) now corresponds to the value of \(\beta\) at the point of maximum curvature on the L-curve.
Experience has shown that the L-curve for the inverse problem considered here does not always have a sharp, distinct corner. The associated slow variation of the curvature with \(\beta\) can make the numerical differentiation required to evaluate eq. (2.60) prone to numerical noise. The line search along the L-curve used in program EM1DTM to find the point of maximum curvature is therefore designed to be robust (rather than efficient). The L-curve is sampled at equally-spaced values of \(\textrm{log} \, \beta\), and long differences are used in the evaluation of eq. (2.60) to introduce some smoothing. A parabola is fit through the point from the equally-spaced sampling with the maximum value of curvature and its two nearest neighbours. The value of \(\beta\) at the maximum of this parabola is taken as \(\beta^*\). In addition, it is sometimes found that, for the range of values of \(\beta\) that are tried, the maximum value of the curvature of the L-curve on logarithmic axes is negative. In this case, the curvature of the L-curve on linear axes is investigated to find a maximum. As for Algorithms 1 & 2, the least-squares solution to eq. (2.53) is used, and is computed using subroutine LSQR of Paige & Saunders ([Paige1982]).
2.3.8. Relative weighting within the model norm¶
The four coefficients in the model norm (see eq. (2.45)) are ultimately the responsibility of the user. Larger values of \(\alpha_s^\sigma\) relative to \(\alpha_z^\sigma\) result in constructed conductivity models that are closer to the supplied reference model. Smaller values of \(\alpha_s^\sigma\) and \(\alpha_z^\sigma\) result in flatter conductivity models. Likewise for the coefficients related to susceptibilities.
If both conductivity and susceptibility are active in the inversion, the relative size of \(\alpha_s^\sigma\) & \(\alpha_z^\sigma\) to \(\alpha_s^\kappa\) & \(\alpha_z^\kappa\) is also required. Program EM1DTM includes a simple means of calculating a default value for this relative balance. Using the layer thicknesses, weighting matrices \(\mathbf{W_s^\sigma}\), \(\mathbf{W_z^\sigma}\), \(\mathbf{W_s^\kappa}\) & \(\mathbf{W_z^\kappa}\), and user-supplied weighting of the smallest and flattest parts of the conductivity and susceptibility components of the model norm (see acs, acz, ass & asz in the input file description, line 5), the following two quantities are computed for a test model \(\mathbf{m}^*\):
The conductivity and susceptibility of the top \(N/5\) layers in the test model are 0.02 S/m and 0.02 SI units respectively, and the conductivity and susceptibility of the remaining layers are 0.01 S/m and 0 SI units. The coefficients of the model norm used in the inversion are then \(\alpha_s^\sigma = acs\), \(\alpha_z^\sigma = acz\), \(\alpha_s^\kappa = A^s \times ass\) & \(\alpha_z^\kappa = A^d \times asz\) where \(A^s \phi_m^\sigma / \phi_m^\kappa\). It has been found that a balance between the conductivity and susceptibility portions of the model norm computed in this way is adequate as an initial guess. However, the balance usually requires modification by the user to obtain the best susceptibility model. (The conductivity model tends to be insensitive to this balance.) If anything, the default balance will suppress the constructed susceptibility model.
2.3.9. Positive susceptibility¶
ProgramEM1DTM can perform an unconstrained inversion for susceptibilities (along with the conductivities)
as well as invert for values of susceptibility that are constrained to be positive. Following Li & Oldenburg
([Li2003]), the positivity constraint is implemented by incorporating a logarithmic barrier term in the objective
function (see eqs. (2.44) & barrier_cond). For the initial iteration, the coefficient of the logarithmic barrier term is chosen
so that this term is of equal important to the rest of the objective function:
At subsequent iterations, the coefficient is reduced according to the formula:
where \(\nu^{n-1}\) is the step length used at the previous iteration. As mentioned at the end of the general formulation, when positivity is being enforced, the step length at any particular iteration must satisfy eq. (2.55).
2.3.10. Convergence criteria¶
To determine when an inversion algorithm has converged, the following criteria are used ([Gill1981]):
where \(\tau\) is a user-specified parameter. The algorithm is considered to have converged when both of the above equations are satisfied. The default value of \(\tau\) is 0.01.
In case the algorithm happens directly upon the minimum, an additional condition is tested:
where \(\epsilon\) is a small number close to zero, and where the gradient, \(\mathbf{g}^n\), at the \(n^{th}\) iteration is given by: